AI Security · Data Boundary
secure-ai-engineering-framework
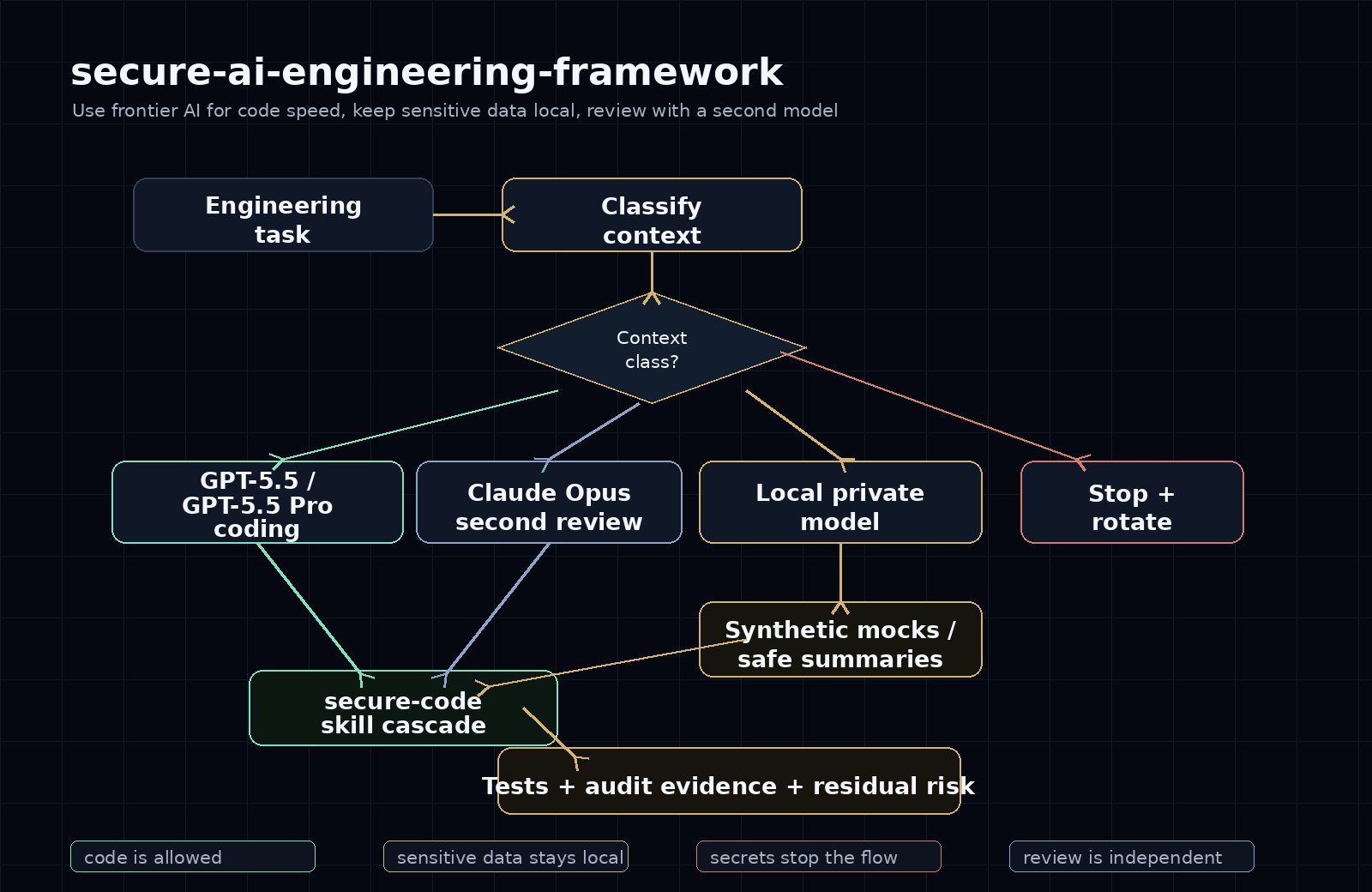
A practical framework for using frontier AI in high-security engineering: GPT-5.5 for code, GPT-5.5 Pro for hard coding, Claude Opus as second reviewer, local models for sensitive data, and private context packs that send only what is needed.
What it includes
- A real Codex `secure-ai-engineering` skill with eleven focused modules.
- Data classes and routing policy for code, private context, sensitive data, and secrets.
- Lightweight prompt classification, synthetic mock generation, context-pack creation, and scenario composition scripts.
- Boundary demos for production data, secrets, repo context minimization, local log summaries, dual review, and incident stop rules.
Why Mirogate built it
High-security teams should not choose between AI speed and data discipline. Code can often be sent to frontier coding models after minimization; production, government, and user data should stay local or become synthetic mocks before external debugging.
npm test
node scripts/classify.mjs --text "export function add(a,b){return a+b}"
node scripts/mock-from-schema.mjs --schema examples/schema/customer-case.schema.json
node scripts/compose.mjs --scenario production-db-debug
This is not a compliance certification, classified-system approval, or legal opinion. It is an engineering framework for using AI quickly while enforcing a hard data boundary.